Experiences with Sun Grid Engine
In October 2007 I updated the Sun Grid Engine installed here at the Department of Statistics and publicised its presence and how it can be used. We have a number of computation hosts (some using Māori fish names as fish are often fast) and a number of users who wish to use the computation power. Matching users to machines has always been somewhat problematic.
Fortunately for us, SGE automatically finds a machine to run compute jobs on. When you submit your job you can define certain characteristics, eg, the genetics people like to have at least 2GB of real free RAM per job, so SGE finds you a machine with that much free memory. All problems solved!
Let's find out how to submit jobs! (The installation and administration section probably won't interest you much.)
I gave a talk on 19 February 2008-02-19 to the Department, giving a quick overview of the need for the grid and how to rearrange tasks to better make use of parallelism.
- Installation
- Administration
- Submitting jobs
- Thrashing the Grid
- Advanced methods of queue submission
- Talk at Department Retreat
- Talk for Department Seminar
- Summary
Installation
My installation isn't as polished as Werner's setup, but it comes with more carrots and sticks and informational emails to heavy users of computing resources.
For this very simple setup I first selected a master host, stat1. This is also the submit host. The documentation explains how to go about setting up a master host.
Installation for the master involved:
- Setting up a configuration file, based on the default configuration.
- Uncompressing the common and architecture-specific binaries into /opt/sge
- Running the installation. (Correcting mistakes, running again.)
- Success!
With the master setup I was ready to add compute hosts. This procedure was repeated for each host. (Thankfully a quick for loop in bash with an ssh command made this step very easy.)
- Login to the host
- Create
/opt/sge. - Uncompress the common and architecture-specific binaries into
/opt/sge - Copy across the cluster configuration from
/opt/sge/default/common. (I'm not so sure on this step, but I get strange errors if I don't do this.) - Add the host to the cluster. (Run qhost on the master.)
- Run the installation, using the configuration file from step 1 of the master. (Correcting mistakes, running again. Mistakes are hidden in
/tmp/install_execd.*until the installation finishes. There's a problem where if/opt/sge/default/common/install_logsis not writeable by the user running the installation then it will be silently failing and retrying in the background. Installation is pretty much instantaneous, unless it's failing silently.)- As a sub-note, you receive architecture errors on Fedora Core. You can fix this by editing
/opt/sge/util/archand changing line 248 that reads3|4|5)to3|4|5|6).
- As a sub-note, you receive architecture errors on Fedora Core. You can fix this by editing
- Success!
If you are now to run qhost on some host, eg, the master, you will now see all your hosts sitting waiting for instructions.
Administration
The fastest way to check if the Grid is working is to run qhost, which lists all the hosts in the Grid and their status. If you're seeing hyphens it means that host has disappeared. Is the daemon stopped, or has someone killed the machine?
The glossiest way to keep things up to date is to use qmon. I have it listed as an application in X11.app on my Mac. The application command is as follows. Change 'master' to the hostname of the Grid master. I hope you have SSH keys already setup.
ssh master -Y . /opt/sge/default/common/settings.sh \; qmonWant to gloat about how many CPUs you have in your cluster? (Does not work with machines that have > 100 CPU cores.)
admin@master:~$ qhost | sed -e 's/^.\{35\}[^0-9]\+//' | cut -d" " -f1
Adding Administrators
SGE will probably run under a user you created it known as "sgeadmin". "root" does not automatically become all powerful in the Grid's eyes, so you probably want to add your usual user account as a Manager or Operator. (Have a look in the manual for how to do this.) It will make your life a lot easier.
Automatically sourcing environment
Normally you have to manually source the environment variables, eg, SGE_ROOT, that make things work. On your submit hosts you can have this setup to be done automatically for you.
Create links from /etc/profile.d to the settings files in /opt/sge/default/common and they'll be automatically sourced for bash and tcsh (at least on Redhat).
Slots
The fastest processing you'll do is when you have one CPU core working on one problem. This is how the Grid is setup by default. Each CPU core on the Grid is a slot into which a job can be put.
If you have people logging on to the machines and checking their email, or being naughty and running jobs by hand instead of via the Grid engine, these calculations get mucked up. Yes, there still is a slot there, but it is competing with something being run locally. The Grid finds a machine with a free slot and the lowest load for when it runs your job so this won't be a problem until the Grid is heavily laden.
Setting up queues
Queues are useful for doing crude prioritisation. Typically a job gets put in the default queue and when a slot becomes free it runs.
If the user has access to more than one queue, and there is a free slot in that queue, then the job gets bumped into that slot.
A queue instance is the queue on a host that it can be run on. 10 hosts, 3 queues = 30 queue instances. In the below example you can see three queues and seven queue instances: all.q@paikea, dnetc.q@paikea, beagle.q@paikea, all.q@exec1, dnetc.q@exec1, all.q@exec2, dnetc.q@exec2. Each queue can have a list of machines it runs on so, for example, the heavy genetics work in beagle.q can be run only on the machines attached to the SAN holding the genetics data. A queue does not have to include all hosts, ie, @allhosts.)
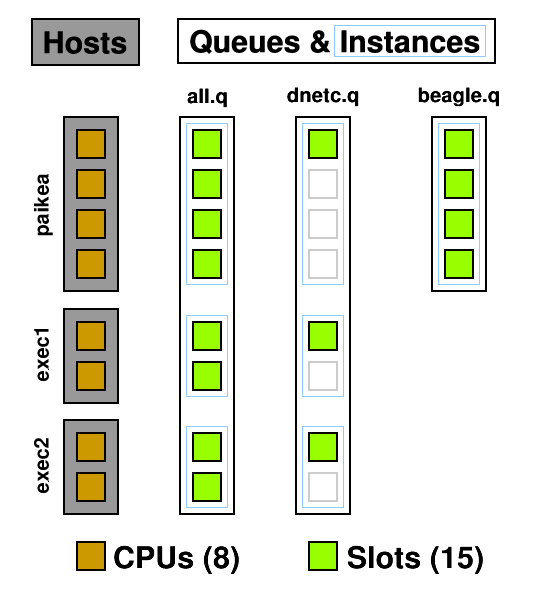
From this diagram you can see how CPUs can become oversubscribed. all.q covers every CPU. dnetc.q covers some of those CPUs a second time. Uh-oh! (dnetc.q is setup to use one slot per queue instance. That means that even if there are 10 CPUs on a given host, it will only use 1 of those.) This is something to consider when setting up queues and giving users access to them. Users can't put jobs into queues they don't have access to, so the only people causing contention are those with access to multiple queues but don't specify a queue (-q) when submitting.
Another use for queues are subordinate queues. I run low priority jobs in dnetc.q. When the main queue gets busy, all the jobs in dnetc.q are suspended until the main queue's load decreases. To do this I edited all.q, and under Subordinates added dnetc.q.
So far the shortest queue I've managed to make is one that uses 1 slot on each host it is allowed to run on. There is some talk in the documentation regarding user defined resources (complexes) which, much like licenses, can be "consumed" by jobs, thus limiting the number of concurrent jobs that can be run. (This may be useful for running an instance of Folding@Home, as it is not thread-safe, so you can set it up with a single "license".)
You can also change the default nice value of processes, but possibly the most useful setting is to turn on "rerunnable", which allows a task to be killed and run again on a different host.
Parallel Environment
Something that works better than queues and slots is to set up a parallel environment
. This can have a limited number of slots which counts over the entire grid and over every queue instance. As an example, Folding@Home is not thread safe. Each running thread needs its own work directory.
How can you avoid contention in this case? Make each working directory a parallel environment, and limit the number of slots to 1.
I have four working directories named fah-a to fah-d. Each contains its own installation of the Folding@Home client:
$ ls ~/grid/fah-a/ fah-a client.cfg FAH504-Linux.exe work
For each of these directories I have created a parallel environment:
admin@master:~$ qconf -sp fah-a pe_name fah-a slots 1 user_lists fah
These parallel environments are made available to all queues that the job can be run in and all users that have access to the working directory - which is just me.
The script to run the client is a marvel of grid arguments. It requests the parallel environment, bills the job to the Folding@Home project, names the project, etc. See for yourself:
#!/bin/sh
# use bash
#$ -S /bin/sh
# current directory
#$ -cwd
# merge output
#$ -j y
# mail at end
#$ -m e
# project
#$ -P fah
# name in queue
#$ -N fah-a
# parallel environment
#$ -pe fah-a 1
./FAH504-Linux.exe -oneunitNote the -pe argument that says this job requires one slot worth of fah-a please.
Not a grid option, but the -oneunit flag for the folding client is important as this causes the job to quit after one work unit and the next work unit can be shuffled around to an appropriate host with a low load whose queue isn't disabled. Otherwise the client could end up running in a disabled queue for a month without nearing an end.
With the grid taking care of the parallel environment I no longer need to worry about manually setting up job holds so that I can enqueue multiple units for the same work directory. -t 1-20 ahoy!
Complex Configuration
An alternative to the parallel environment is to use a Complex. You create a new complex, say how many slots are available, and then let people consume them!
- In the QMON Complex Configuration, add a complex called "fah_l", type INT, relation <=, requestable YES, consumable YES, default 0. Add, then Commit.
- I can't manage to get this through QMON, so I do it from the command line. qconf -me global and then add fah_l=1 to the complex_values.
- Again through the command line. qconf -mq all.q and then add fah_l=1 to the complex_values. Change this value for the other queues. (Note that a value of 0 means jobs requesting this complex cannot be run in this queue.)
- When starting a job, add -l fah_l=1 to the requirements.
I had a problem to start off with, where qstat was telling me that -25 licenses were available. However this is due to the default value, so make sure that is 0!
Using Complexes I have set up license handling for Matlab and Splus.
- -l splus=1 (to request a Splus license)
- -l matlab=1 (to request a Matlab license)
- -l ml=1,matlabc=1 (to request a Matlab license and a Matlab Compiler license)
- -l ml=1,matlabst=1 (to request a Matlab license and a Matlab Statistics Toolbox license)
As one host group does not have Splus installed on them I simply set that host group to have 0 Splus licenses available. A license will never be available on the @gradroom host group, thus Splus jobs will never be queued there.
Quotas
Instead of Complexes and parallel environments, you could try a quota!
Please excuse the short details:
admin@master$ qconf -srqsl
admin@master$ qconf -mrqs lm2007_slots
{
name lm2007_slots
description Limit the lm2007 project to 20 slots across the grid
enabled TRUE
limit projects lm2007 to slots=20
}
Pending jobs
Want to know why a job isn't running?
- Job Control
- Pending Jobs
- Select a job
- Why ?
This is the same as qstat -f, shown at the bottom of this page.
Using Calendars
A calendar is a list of days and times along with states: off or suspended. Unless specified the state is on.
A queue, or even a single queue instance, can have a calendar attached to it. When the calendar says that the queue should now be "off" then the queue enters the disabled (D) state. Running jobs can continue, but no new jobs are started. If the calendar says it should be suspended then the queue enters the suspended (S) state and all currently running jobs are stopped (SIGSTOP).
First, create the calendar. We have an upgrade for paikea scheduled for 17 January:
admin@master$ qconf -scal paikeaupgrade
calendar_name paikeaupgrade
year 17.1.2008=off
week NONE
By the time we get around to opening up paikea's case and pull out the memory jobs will have had several hours to complete after the queue is disabled. Now, we have to apply this calendar to every queue instance on this host. You can do this all through qmon but I'm doing it from the command line because I can. Simply edit the calendar line to append the hostname and calendar name:
admin@master$ qconf -mq all.q ... calendar NONE,[paikea=paikeaupgrade] ...
Repeat this for all the queues.
There is a user who likes to use one particular machine and doesn't like jobs running while he's at the console. Looking at the usage graphs I've found out when he is using the machine and created a calendar based on this:
admin@master$ qconf -scal michael
calendar_name michael
year NONE
week mon-sat=13-21=off
This calendar is obviously recurring weekly. As in the above example it was applied to queues on his machine. Note that the end time is 21, which covers the period from 2100 to 2159.
Suspending jobs automatically
Due to the number of slots being equal to the number of processors, system load is theoretically not going to exceed 1.00 (when divided by the number of processors). This value can be found in the np_load_* complexes.
But (and this is a big butt) there are a number of ways in which the load could go past a reasonable level:
- There are interactive users: all of the machines in the grad room (@gradroom) have console access.
- Someone logged in when they should not have: we're planning to disable ssh access to @ngaika except for %admins.
- A job is multi-threaded, and the submitter didn't mention this. If your Java program is using 'new Thread' somewhere, then it's likely you'll end up using multiple CPUs. Request more than one CPU when you're submitting the job. (-l slots=4 does not work.)
For example, with paikea, there are three queues:
- all.q (4 slots)
- paikea.q (4 slots)
- beagle.q (overlapping with the other two queues)
all.q is filled first, then paikea.q. beagle.q, by project and owner restrictions, is only available to the sponsor of the hardware. When their jobs come in, they can get put into beagle.q, even if the other slots are full. When the load average comes up, other tasks get suspended: first in paikea.q, then in all.q.
Let's see the configuration:
qname beagle.q hostlist paikea.stat.auckland.ac.nz priority 19,[paikea.stat.auckland.ac.nz=15] user_lists beagle projects beagle
We have the limited access to this queue through both user lists and projects. Also, we're setting the Unix process priority to be higher than the other queues.
qname paikea.q hostlist paikea.stat.auckland.ac.nz suspend_thresholds NONE,[paikea.stat.auckland.ac.nz=np_load_short=1.01] nsuspend 1 suspend_interval 00:05:00 slots 0,[paikea.stat.auckland.ac.nz=4]
The magic here being that suspend_thresholds is set to 1.01 for np_load_short. This is checked every 5 minutes, and 1 process is suspended at a time. This value can be adjusted to get what you want, but it seems to be doing the trick according to graphs and monitoring the load. np_load_short is chosen because it updates the most frequently (every minute), more than np_load_medium (every five), and np_load_long (every fifteen minutes).
all.q is fairly unremarkable. It just defines four slots on paikea.
Submitting jobs
Jobs are submitted to the Grid using qsub. Jobs are shell scripts containing commands to be run.
If you would normally run your job by typing ./runjob, you can submit it to the Grid and have it run by typing: qsub -cwd ./runjob
Jobs can be submitted while logged on to any submit host: sge-submit.stat.auckland.ac.nz.
For all the commands on this page I'm going to assume the settings are all loaded and you are logged in to a submit host. If you've logged in to a submit host then they'll have been sourced for you. You can source the settings yourself if required: . /opt/sge/default/common/settings.sh - the dot and space at the front are important.
Depending on the form your job is currently in they can be very easy to submit. I'm just going to go ahead and assume you have a shell script that runs the CPU-intensive computations you want and spits them out to the screen. For example, this tiny test.sh:
#!/bin/sh
expr 3 + 5This computation is very CPU intensive!
Please note that the Sun Grid Engine ignores the bang path at the top of the script and will simply run the file using the queue's default shell which is csh. If you want bash, then request it by adding the very cryptic line: #$ -S /bin/sh
Now, let's submit it to the grid for running: Skip submission output
user@submit:~$ qsub test.sh
Your job 464 ("test.sh") has been submitted
user@submit:~$ qstat
job-ID prior name user state submit/start at queue slots ja-task-ID
-------------------------------------------------------------------------------------------------------
464 0.00000 test.sh user qw 01/10/2008 10:48:03 1
There goes our job, waiting in the queue to be run. We can run qstat a few more times to see it as it goes. It'll be run on some host somewhere, then disappear from the list once it is completed. You can find the output by looking in your home directory: Skip finding output
user@submit:~$ ls test.sh* test.sh test.sh.e464 test.sh.o464 user@submit:~$ cat test.sh.o464 8
The output file is named based on the name of the job, the letter o, and the number of the job.
If your job had problems running have a look in these files. They probably explain what went wrong.
Easiest way to submit R jobs
Here are two scripts and a symlink I created to make it easy as possible to submit R jobs to your Grid:
qsub-R
If you normally do something along the lines of:
user@exec:~$ nohup nice R CMD BATCH toodles.R
Now all you need to do is:
user@submit:~$ qsub-R toodles.R
Your job 3540 ("toodles.R") has been submitted
qsub-R is linked to submit-R, a script I wrote. It calls qsub and submits a simple shell wrapper with the R file as an argument. It ends up in the queue and eventually your output arrives in the current directory: toodles.R.o3540
Download it and install it. You'll need to make the 'qsub-R' symlink to '3rd_party/uoa-dos/submit-R' yourself, although there is one in the package already for lx24-x86: qsub-R.tar (10 KiB, tar)
Thrashing the Grid
Sometimes you just want to give something a good thrashing, right? Never experienced that? Maybe it's just me. Anyway, here are two ideas for submitting lots and lots of jobs:
- Write a script that creates jobs and submits them
- Submit the same thing a thousand times
There are merits to each of these methods, and both of them mimic typical operation of the grid, so I'm going to explain them both.
Computing every permutation
If you have two lists of values and wish to calculate every permutation, then this method will do the trick. There's a more complicated solution below.
qsub will happily pass on arguments you supply to the script when it runs. Let us modify our test.sh to take advantage of this:
#!/bin/sh
#$ -S /bin/sh
echo Factors $1 and $2
expr $1 + $2Now, we just need to submit every permutation to Grid:
user@submit:~$ for A in 1 2 3 4 5 ; do for B in 1 2 3 4 5 ; do qsub test.sh $A $B ; done ; done
Away the jobs go to be computed. If we have a look at different jobs we can see that it works. For example, job 487 comes up with:
user@submit:~$ cat test.sh.?487 Factors 3 and 5 8
Right on, brother! That's the same answer as we got previously when we hard coded the values of 3 and 5 into the file. We have algorithm correctness!
If we use qacct to look up the job information we find that it was computed on host mako (shark) and used 1 units of wallclock and 0 units of CPU.
Computing every permutation, with R
This method of creating job scripts and running them will allow you to compute every permutation of two variables. Note that you can supply arguments to your script, so it is not actually necessary to over-engineer your solution quite this much. This script has the added advantage of not clobbering previous computations. I wrote this solution for Yannan Jiang and Chris Wild and posted it to the r-downunder mailing list in December 2007. (There is another method of doing this!)
In this particular example the output of the R command is deterministic, so it does not matter that a previous run (which could have taken days of computing time) gets overwritten, however I also work around this problem.
To start with I have my simple template of R commands (template.R):
alpha <- ALPHA
beta <- c(BETA)
# magic happens here
alpha
betaThe ALPHA and BETA parameters change for each time this simulation is run. I have these values stored, one per line, in the files ALPHA and BETA.
ALPHA:
0.9 0.8 0.7
BETA (please note that these contents must work both in filenames, bash commands, and R commands):
0,0,1 0,1,0 1,0,0
I have a shell script that takes each combination of ALPHA x BETA, creates a .R file based on the template, and submits the job to the Grid. This is called submit.sh:
#!/bin/sh
if [ "X${SGE_ROOT}" == "X" ] ; then
echo Run: . /opt/sge/default/common/settings.sh
exit
fi
cat ALPHA | while read ALPHA ; do
cat BETA | while read BETA ; do
FILE="t-${ALPHA}-${BETA}"
# create our R file
cat template.R | sed -e "s/ALPHA/${ALPHA}/" -e "s/BETA/${BETA}/" > ${FILE}.R
# create a script
echo \#!/bin/sh > ${FILE}.sh
echo \#$ -S /bin/sh >> ${FILE}.sh
echo "if [ -f ${FILE}.Rout ] ; then echo ERROR: output file exists already ; exit 5 ; fi" >> ${FILE}.sh
echo R CMD BATCH ${FILE}.R ${FILE}.Rout >> ${FILE}.sh
chmod +x ${FILE}.sh
# submit job to grid
qsub -j y -cwd ${FILE}.sh
done
done
qstatWhen this script runs it will, for each permutation of ALPHA and BETA,
- create an R file based on the template, filling in the values of ALPHA and BETA,
- create a script that checks if this permutation has been calculated and then calls R,
- submits this job to the queue
... and finally shows the jobs waiting in the queue to execute.
Once computation is complete you will have a lot of files waiting in your directory. You will have:
- template.R -- our R commands template
- t-ALPHA-BETA.sh -- generated shell script that calls R
- t-ALPHA-BETA.R -- generated (from template) R commands
- t-ALPHA-BETA.Rout -- output from the command; this is a quirk of R
- t-ALPHA-BETA.sh.oNNN -- any output or errors from job (merged using qsub -j y)
The output files, stderr and stdout from when R was run, are always empty (unless something goes terribly wrong). For each permutation we receive four files. There are nine permutations (nALPHA = 3, nBETA = 3, 3 × 3 = 9). A total of 36 files are created. (This example has been pared down from the original for purposes of demonstration.)
My initial question to the r-downunder list was how to get the output from R to stdout and thus t-ALPHA-BETA.sh.oNNN instead of t-ALPHA-BETA.Rout, however in this particular case, I have dodged that. In fact, being deterministic it is better that this job writes its output to a known filename, so I can do a one line test to see if the job has already been run.
I should also point out the -cwd option to the qsub command, which causes the job to be run in the current directory (which if it is in your home directory is accessible in the same place on all machines), rather than in /tmp/*. This allows us to find the R output, since R writes it to the directory it is currently in. Otherwise it could be discarded as a temporary file once the job ends!
Submit the same thing a thousand times
Say you have a job that, for example, pulls in random numbers and runs a simulation, or it grabs a work unit from a server, computes it, then quits. (FAH -oneunit springs to mind, although it cannot be run in parallel. Refer to the parallel environment setup.) The script is identical every time.
SGE sets the SGE_JOB_ID environment variable which tells you the job number. You can use this as some sort of crude method for generating a unique file name for your output. However, the best way is to write everything to standard output (stdout) and let the Grid take care of returning it to you.
There are also Array Jobs which are identical tasks being differentiated only by an index number
, available through the -t option on qsub. This sets the environment variable of SGE_TASK_ID.
For this example I will be using the Distributed Sleep Server. The Distributed Sleep Project passes out work units, packages of time, to clients who then process the unit. The Distributed Sleep Client, dsleepc, connects to the server to fetch a work unit. They can then be processed using the sleep command. A sample script: Skip sample script
#!/bin/sh
#$ -S /bin/sh
WORKUNIT=`dsleepc`
sleep $WORKUNIT && echo Processed $WORKUNIT secondsWork units of 300 seconds typically take about five minutes to complete, but are known to be slower on Windows. (The more adventurous can add the -bigunit option to get a larger package for themselves, but note that they take longer to process.)
So, let us submit an array job to the Grid. We are going to submit one job with 100 tasks, and they will be numbered 1 to 100:
user@submit:~$ qsub -t 1-100 dsleep
Your job-array 490.1-100:1 ("dsleep") has been submitted
Job 490, tasks 1 to 100, are waiting to run. Later we can come back and pick up our output from our home directory. You can also visit the Distributed Sleep Project and check the statistics server to see if your work units have been received.
Note that running 100 jobs will fill the default queue, all.q. This has two effects. First, if you have any other queues that you can access jobs will be added to those queues and then run. (As the current setup of queues overlaps with CPUs this can lead to over subscription of processing resources. This can cause jobs to be paused, depending on how the queue is setup.) Second, any subordinate queues to all.q will be put on hold until the jobs get freed up.
Array jobs, with R
Using the above method of submitting multiple jobs, we can access this and use it in our R script, as follows: Skip R script
# alpha+1 is found in the SGE TASK number (qsub -t)
alphaenv <- Sys.getenv("SGE_TASK_ID")
alpha <- (as.numeric(alphaenv)-1)Here the value of alpha is being pulled from the task number. Some manipulation is done of it, first to turn it from a string into a number, and secondly to change it into the expected form. Task numbers run from 1+, but in this case the code wants them to run from 0+.
Similar can be done with Java, by adding the environment value as an argument to invocation of the main class.
Advanced methods of queue submission
When you submit your job you have a lot of flexibility over it. Here are some options to consider that may make your life easier. Remember you can always look in the man page for qsub for more options and explanations.
qsub -N timmy test.sh
Here the job is called "timmy" and runs the script test.sh . Your the output files will be in timmy.[oe]*
The working directory is usually somewhere in /tmp on the execution host. To use a different working directory, eg, the current directory, use -cwd
qsub -cwd test.sh
To request specific characteristics of the execution host, for example, sufficient memory, use the -l argument.
qsub -l mem_free=2500M test.sh
This above example requests 2500 megabytes (M = 1024x1024, m = 1000x1000) of free physical memory (mem_free) on the remote host. This means it won't be run on a machine that has 2.0GB of memory, and will instead be put onto a machine with sufficient amounts of memory for BEAGLE Genetic Analysis. There are two other options for ensuring you get enough memory:
- Submit your job to the BEAGLE queue: -q beagle.q . This queue is specifically setup only on machines with a lot of free memory, and has 10 slots. You do have to be one of the allowed BEAGLE users to put jobs into this queue.
- Specify the amount of memory required in your script:
#$ -l mem=2500
If your binary is architecture dependent you can ask for a particular architecture.
qsub -l arch=lx24-amd64 test.bin
This can also be done in the script that calls the binary so you don't accidentally forget about including it.
#$ -l arch=lx24-amd64This requesting of resources can also be used to ask for a specific host, which goes against the idea of using the Grid to alleviate finding a host to use! Don't do this!
qsub -l hostname=mako test.sh
If your job needs to be run multiple times then you can create an array job. You ask for a job to be run several times, and each run (or task) is given a unique task number which can be accessed through the environment variable SGE_TASK_ID. In each of these examples the script is run 50 times:
qsub -t 1-50 test.sh qsub -t 75-125 test.sh
You can request a specific queue. Different queues have different characteristics.
- lm2007.q uses a maximum of one slot per host (although once I figure out how to configure it, it will use a maximum of six slots Grid-wide).
- dnetc.q is suspended when the main queue (all.q) is busy.
- beagle.q runs only on machines with enough memory to handle the data (although this can be requested with -l, as shown above).
qsub -q dnetc.q test.sh
A job can be held until a previous job completes. For example, this job will not run until job 380 completes:
qsub -hold_jid 380 test.sh
Can't figure out why your job isn't running? qstat can tell you:
qstat -j 490
... lots of output ...
scheduling info: queue instance "dnetc.q@mako.stat.auckland.ac.nz" dropped because it is temporarily not available
queue instance "dnetc.q@patiki.stat.auckland.ac.nz" dropped because it is full
cannot run in queue "all.q" because it is not contained in its hard queue list (-q)
Requesting licenses
Should you be using software that requires licenses then you should specify this when you submit the job. We have two licenses currently set up but can easily add more as requested:
- -l splus=1 (to request a Splus license)
- -l matlab=1 (to request a Matlab license)
- -l ml=1,matlabc=1 (to request a Matlab license and a Matlab Compiler license)
- -l ml=1,matlabst=1 (to request a Matlab license and a Matlab Statistics Toolbox license)
The Grid engine will hold your job until a Splus license or Matlab license becomes available.
Note: The Grid engine keeps track of the license pool independently of the license manager. If someone is using a license that the Grid doesn't know about, eg, an interactive session you left running on your desktop, then the count will be off. Believing a license is available, the Grid will run your job, but Splus will not run and your job will end. Here is a job script that will detect this error and then allow your job to be retried later: Skip Splus script
#!/bin/sh
#$ -S /bin/bash
# run in current directory, merge output
#$ -cwd -j y
# name the job
#$ -N Splus-lic
# require a single Splus license please
#$ -l splus=1
Splus -headless < $1
RETVAL=$?
if [ $RETVAL == 1 ] ; then
echo No license for Splus
sleep 60
exit 99
fi
if [ $RETVAL == 127 ] ; then
echo Splus not installed on this host
# you could try something like this:
#qalter -l splus=1,h=!`hostname` $JOB_ID
sleep 60
exit 99
fi
exit $RETVALPlease note that the script exits with code 99 to tell the Grid to reschedule this job (or task) later. Note also that the script, upon receiving the error, sleeps for a minute before exiting, thus slowing the loop of errors as the Grid continually reschedules the job until it runs successfully. Alternatively you can exit with error 100, which will cause the job to be held in the error (E) state until manually cleared to run again.
You can clear a job's error state by using qmod -c jobid.
Here's the same thing for Matlab. Only minor differences from running Splus: Skip Matlab script
#!/bin/sh
#$ -S /bin/sh
# run in current directory, merge output
#$ -cwd -j y
# name the job
#$ -N ml
# require a single Matlab license please
#$ -l matlab=1
matlab -nodisplay < $1
RETVAL=$?
if [ $RETVAL == 1 ] ; then
echo No license for Matlab
sleep 60
exit 99
fi
if [ $RETVAL == 127 ] ; then
echo Matlab not installed on this host, `hostname`
# you could try something like this:
#qalter -l matlab=1,h=!`hostname` $JOB_ID
sleep 60
exit 99
fi
exit $RETVALSave this as "run-matlab". To run your matlab.m file, submit with: qsub run-matlab matlab.m
Processing partial parts of input files in Java
Here is some code I wrote for Lyndon Walker to process a partial dataset in Java.
It comes with two parts: a job script that passes the correct arguments to Java, and some Java code that extracts the correct information from the dataset for processing.
First, the job script gives some Grid task environment variables to Java. Our job script is merely translating from the Grid to the simulation:
java Simulation $@ $SGE_TASK_ID $SGE_TASK_LASTThis does assume your shell is bash, not csh. If your job is in 10 tasks, then SGE_TASK_ID will be a number between 1 and 10, and SGE_TASK_LAST will be 10. I'm also assuming that you are starting your jobs from 1, but you can also change that setting and examine SGE_TASK_FIRST.
Within Java we now read these variables and act upon them:
sge_task_id = Integer.parseInt(args[args.length-2]);
sge_task_last = Integer.parseInt(args[args.length-1]);For a more complete code listing, refer to sun-grid-qsub-java-partial.java (Simulation.java).
Preparing confidential datasets
The Grid setup here includes machines on which users can login. That creates the problem where someone might be able to snag a confidential dataset that is undergoing processing. One particular way to keep the files secure is as follows:
- Check we are able to securely delete files
- Locate a safe place to store files locally (the Grid sets up ${TMPDIR} to be unique for this job and task)
- Copy over dataset; it is expected you have setup password-less scp
- Preprocess dataset, eg, unencrypt
- Process dataset
- Delete dataset
A script that does this would look like the following: Skip dataset preparation script
#!/bin/sh
#$ -S /bin/sh
DATASET=confidential.csv
# check our environment
umask 0077
cd ${TMPDIR}
chmod 0700 .
# find srm
SRM=`which srm`
NOSRM=$?
if [ $NOSRM -eq 1 ] ; then
echo system srm not found on this host, exiting >> /dev/stderr
exit 99
fi
# copy files from data store
RETRIES=0
while [ ${RETRIES} -lt 5 ] ; do
((RETRIES++))
scp user@filestore:/store/confidential/${DATASET} .
if [ $? -eq 0 ] ; then
RETRIES=5000
else
# wait for up to a minute (MaxStartups 10 by default)
sleep `expr ${RANDOM} / 542`
fi
done
if [ ! -f ${DATASET} ] ; then
# unable to copy dataset after 5 retries, quit but retry later
echo unable to copy dataset from store >> /dev/stderr
exit 99
fi
# if you were decrypting the dataset, you would do that here
# copy our code over too
cp /mount/code/*.class .
# process data
java Simulation ${DATASET}
# collect results
# (We are just printing to the screen.)
# clean up
${SRM} -v ${DATASET} >> /dev/stderr
echo END >> /dev/stderrCode will need to be adjusted to match your particular requirements, but the basic form is sketched out above.
As the confidential data is only in files and directories that root and the running user can access, and the same precaution is taken with the datastore, then only the system administrator and the user who has the dataset has access to these files.
The one problem here is how to manage the password-less scp securely. As this is run unattended, it would not be possible to have a password on a file, nor to forward authentication to some local agent. It may be possible to grab the packets that make up the key material. There must be a better way to do this. Remember that the job script is stored world-readable in the Grid cell's spool, so nothing secret can be put in there either.
Talk at Department Retreat
I gave a talk about the Sun Grid Engine on 19 February 2008-02-19 to the Department, giving a quick overview of the need for the grid and how to rearrange tasks to better make use of parallelism. It was aimed at end users and summarises into neat slides the reason for using the grid engine as well as a tutorial and example on how to use it all.
Download: Talk (with notes) PDF 5.9MiB
Question time afterwards was very good. Here are, as I recall them, the questions and answers.
Which jobs are better suited to parallelism?
Q (Ross Ihaka): Which jobs are better suited to parallelism? (Jobs with large data sets do not lend themselves to this sort of parallelism due to I/O overheads.)
A: Most of the jobs being used here are CPU intensive. The grid copies your script to /tmp on the local machine on which it runs. You could copy your data file across as well at the start of the job, thus all your later I/O is local.
(This is a bit of a poor answer. I wasn't really expecting it.) Bayesian priors and multiple identical simulations (eg, MCMC differing only by random numbers) lend themselves well to being parallelised.
Can I make sure I always run on the fastest machine?
A: The grid finds the machine with the least load to run jobs on. If you pile all jobs onto one host, then that host will slow down and become the slowest overall. Submit it through the grid and some days you'll get the fast host, and some days you'll get the slow host, and it is better in the long run. Also it is fair for other users. You can force it with -l, however, it is selfish.
Preemptable queues?
Q (Nicholas Horton): Is there support for preemptable queues? A person who paid for a certain machine might like it to be available only to them when they require it all for themselves.
A: Yes, the Grid has support for queues like that. It can all be configured. This particular example will have to be looked in to further. Beagle.q, as an example, only runs on paikea and overlaps with all.q . Also when the load on paikea, again using that as an example, gets too high, jobs in a certain queue (dnetc.q) are stopped.
An updated answer: the owner of a host can have an exclusive queue that preempts the other queues on the host. When the system load is too high, less important jobs can be suspended using suspend_thresholds.
Is my desktop an execution host?
Q (Ross Ihaka): Did I see my desktop listed earlier?
A: No. So far the grid is only running on the servers in the basement and the desktops in the grad room. Desktops in staff offices and used by PhD candidates will have to opt in.
(Ross Ihaka) Offering your desktop to run as an execution host increases the total speed of the grid, but your desktop may run slower at times. It is a two way street.
Is there job migration?
A: It's crude, and depends on your job. If something goes wrong (eg, the server crashes, power goes out) your job can be restarted on another host. When queue instances become unavailable (eg, we're upgrading paikea) they can send a signal to your job, telling it to save its work and quit, then can be restarted on another host.
Migration to faster hosts
Q (Chris Wild): What happens if a faster host becomes available while my job is running?
A: Nothing. Your job will continue running on the host it is on until it ends. If a host is overloaded, and not due to the grid's fault, some jobs can be suspended until load decreases. The grid isn't migrating jobs. The best method is to break your job down into smaller jobs, so that when the next part of the job is started it gets put onto what is currently the best available host.
Over sufficient jobs it will become apparent that the faster host is processing more jobs than a slower host.
Desktops and calendars
Q (Stephane Guindon): What about when I'm not at my desktop. Can I have my machine be on the grid then, and when I get to the desktop the jobs are migrated?
A: Yes, we can set up calendars so that at certain times no new jobs will be started on your machine. Jobs that are already running will continue until they end. (Disabling the queue.) Since some jobs run for days this can appear to have no influence on how many jobs are running. Alternatively jobs can be paused, which frees up the CPU, but leaves the job sitting almost in limbo. (Suspending the queue.) Remember the grid isn't doing migration. It can stop your job and run it elsewhere (if you're using the -notify option on submission and handling the USR1 signal).
Jobs under the grid
Q (Sharon Browning): How can I tell if a job is running under the grid's control? It doesn't show this under top.
A: Try ps auxf . You will see the job taking a lot of CPU time, the parent script, and above that the grid (sge_shepherd and sge_execd).
Talk for Department Seminar
On September 11 I gave a talk to the Department covering:
- Trends in Supercomputing
- Increase in power
- Increase in power consumption
- Increase in data
- Collection of servers
- Workflows
- Published services
- Collaboration
- How to use it
- Jargon
- Taking advantage of more CPUs
- Rewriting your code
- Case Studies
- Increasing your Jargon
- Question time
Download slides with extensive notes: Supercomputing and You (PDF 3MiB)
A range of good questions:
- What about psuedo-random number generators being initialised with the same seed?
- How do I get access to these resources if I'm not a researcher here?
- How do I get access to this Department's resources?
- Do Windows programs (eg, WinBUGS) run on the Grid?
Summary
In summary, I heartily recommend the Sun Grid Engine. After a few days installation, configuring, messing around, I am very impressed with what can be done with it.
Try it today.